 BigSift Example
BigSift Example
Abstract
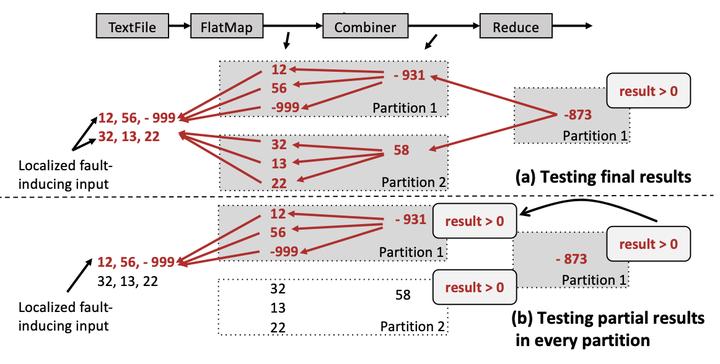
Developing Big Data Analytics workloads often involves trial and error debugging, due to the unclean nature of datasets or wrong assumptions made about data. When errors (e.g., program crash, outlier results, etc.) arise, developers are often interested in identifying a subset of the input data that is able to reproduce the problem. BigSift is a new faulty data localization approach that combines insights from automated fault isolation in software engineering and data provenance in database systems to find a minimum set of failure-inducing inputs. BigSift redefines data provenance for the purpose of debugging using a test oracle function and implements several unique optimizations, specifically geared towards the iterative nature of automated debugging workloads. BigSift improves the accuracy of fault localizability by several orders-of-magnitude (∼103 to 107×) compared to Titian data provenance, and improves performance by up to 66× compared to Delta Debugging, an automated fault-isolation technique. For each faulty output, BigSift is able to localize fault-inducing data within 62% of the original job running time.
Xueyuan Michael Han-Vanbastelaer
Assistant Professor
My research interests include systems security and privacy, data provenance, and graph analysis.